
Introduction
Alibaba’s latest AI model, Qwen2.5-Max, is making waves in the artificial intelligence landscape with its impressive benchmark results. Trained on over 20 trillion tokens, the model has demonstrated superior performance across various AI benchmarks, challenging established models such as DeepSeek-V3, Llama 3, GPT-4o, and Claude 3.5 Sonnet. These results highlight Qwen2.5-Max’s strength in reasoning, knowledge retrieval, programming tasks, and real-world AI applications.
This article explores the benchmark results of Qwen2.5-Max, comparing its performance to its competitors and analyzing its potential impact on the AI ecosystem.
Italy’s Privacy Watchdog Blocks DeepSeek AI: A GDPR Battle Begins
Benchmark Performance Overview
The following benchmarks measure general AI performance, reasoning abilities, programming capabilities, and real-world knowledge retrieval. Qwen2.5-Max dominates in several categories, positioning itself as a major competitor in the AI race.
AI Weekly Roundup: Major Industry Moves Reshape the Landscape
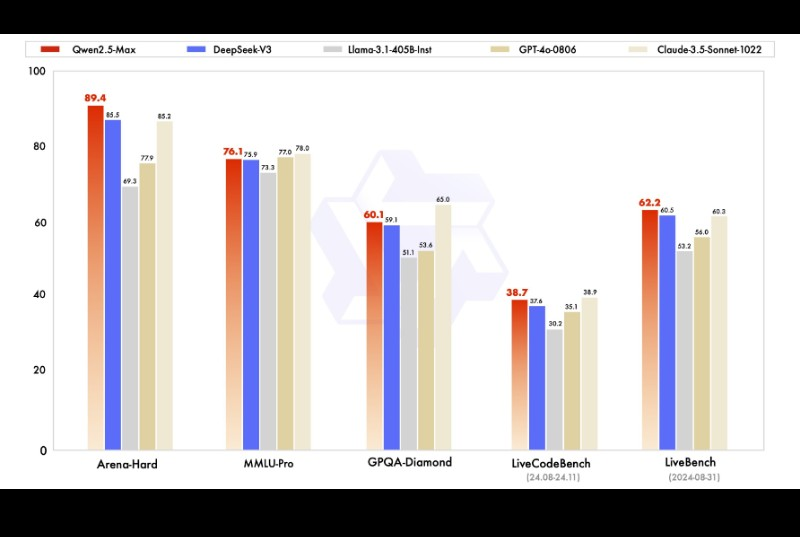
1. Arena-Hard
- Qwen2.5-Max: 89.4 (Highest Score)- DeepSeek-V3: 85.5- Claude 3.5 Sonnet: 85.2- GPT-4o: 77.9- Llama 3.1 (4058 Inst.): 69.3
Analysis: The Arena-Hard benchmark measures a model’s ability to handle complex reasoning tasks and generate high-quality responses. Qwen2.5-Max outperformed all competitors, including Claude 3.5 Sonnet and DeepSeek-V3, showing strong problem-solving capabilities.
Navigating the Next Frontier of AI: From Infrastructure to Intelligent Agents
2. MMLU-Pro (Massive Multitask Language Understanding)
- Claude 3.5 Sonnet: 78.0 (Highest)- GPT-4o: 77.0- Qwen2.5-Max: 76.1- DeepSeek-V3: 75.9- Llama 3.1 (4058 Inst.): 73.8
Analysis: The MMLU-Pro benchmark evaluates multidisciplinary knowledge and reasoning ability across various subjects. While Claude 3.5 Sonnet took the lead with 78.0, Qwen2.5-Max secured third place with 76.1, just 0.9 points behind GPT-4o. This result demonstrates that Qwen2.5-Max is highly competitive in general knowledge and reasoning tasks.
3. GPQA-Diamond (General-Purpose Question Answering)
- Qwen2.5-Max: 60.1 (Highest Score)- Claude 3.5 Sonnet: 59.9- DeepSeek-V3: 53.6- GPT-4o: 51.3- Llama 3.1 (4058 Inst.): 45.0
Analysis: GPQA-Diamond measures question-answering capabilities on complex, knowledge-intensive queries. Qwen2.5-Max took the top spot, narrowly beating Claude 3.5 Sonnet. The significant gap over DeepSeek-V3 and GPT-4o indicates superior knowledge retrieval and contextual understanding.
4. LiveCodeBench (Programming & Code Generation)
- Qwen2.5-Max: 38.7 (Highest Score)- Claude 3.5 Sonnet: 37.6- DeepSeek-V3: 35.4- GPT-4o: 30.2- Llama 3.1 (4058 Inst.): 30.2
Analysis: LiveCodeBench tests AI coding capabilities, measuring accuracy in code generation, debugging, and logic handling. Qwen2.5-Max scored highest, slightly ahead of Claude 3.5 Sonnet. GPT-4o and Llama 3.1 trailed significantly, reinforcing Qwen2.5-Max’s strength in AI-assisted programming.
5. LiveBench (General AI Task Performance)
- Qwen2.5-Max: 62.2 (Highest Score)- DeepSeek-V3: 60.5- Claude 3.5 Sonnet: 50.6- GPT-4o: 46.0- Llama 3.1 (4058 Inst.): 40.3
Analysis: LiveBench evaluates real-world AI applications, including reasoning, task execution, and adaptive responses. Qwen2.5-Max scored highest, demonstrating strong adaptability and practical performance.
DeepSeek Reports Major Cyberattack Amid Rapid Growth
Key Takeaways
- Qwen2.5-Max excels in multiple AI benchmarks, taking first place in Arena-Hard, GPQA-Diamond, LiveCodeBench, and LiveBench.2. It competes closely with Claude 3.5 Sonnet in MMLU-Pro and GPQA-Diamond, proving its strength in general knowledge tasks.3. It surpasses GPT-4o, DeepSeek-V3, and Llama 3.1 across all tests, marking it as a formidable competitor in the AI space.4. Qwen2.5-Max performs exceptionally well in programming tasks (LiveCodeBench), suggesting strong potential for AI-assisted software development.
Impact on the AI Landscape
With these impressive results, Qwen2.5-Max is poised to challenge industry leaders like OpenAI, Google DeepMind, and Anthropic. Alibaba’s investment in AI research is paying off, and Qwen2.5-Max’s competitive performance could lead to more diverse AI solutions across industries.
The strong coding capabilities (LiveCodeBench) make it a valuable tool for developers, and its high scores in reasoning and knowledge retrieval (GPQA-Diamond, MMLU-Pro) suggest broad applications in research, enterprise AI, and general AI use cases.
Potential Use Cases
- Enterprise AI Solutions: AI-driven decision-making, automation, and analytics.- AI-Assisted Programming: Enhanced code generation, debugging, and software automation.- Knowledge-Based AI Systems: Chatbots, knowledge retrieval, and research assistance.- General-Purpose AI Applications: Smart assistants, AI-powered content creation, and automated workflows.
Privacy Concerns DeepSeek and Qwen AI models
There are notable privacy concerns associated with both DeepSeek and Qwen AI models, particularly regarding data collection, storage, and usage as outlined in their terms of service and privacy policies.
DeepSeek:
- Data Collection and Storage: DeepSeek’s privacy policy indicates that it collects user inputs, including text, audio, uploaded files, feedback, and chat history. This information is stored on servers located in the People’s Republic of China.- Data Usage: The policy states that DeepSeek may use collected information to improve services, conduct research, and comply with legal obligations. However, the extent of data sharing with third parties, including potential access by the Chinese government, has raised significant concerns.- Censorship and Content Moderation: Reports have highlighted that DeepSeek employs censorship mechanisms, particularly on topics sensitive to the Chinese government, such as the Tiananmen Square protests and issues related to Taiwan. This raises questions about the model’s objectivity and the potential suppression of information.
Qwen:
- Data Collection and Storage: Information regarding Qwen’s data collection and storage practices is limited. However, given that Qwen is developed by Alibaba, a Chinese company, it’s plausible that user data may be stored on servers within China.- Terms of Service: Qwen’s terms of service prohibit users from infringing upon intellectual property or other legal rights, including rights of privacy. While this indicates a commitment to user privacy, the specifics of data handling and potential sharing with third parties are not clearly detailed.
General Considerations:
Users should exercise caution when using AI models developed by entities subject to jurisdictions with differing data privacy regulations. The potential for data access by governmental authorities, as well as varying standards for data protection, necessitates careful consideration.
Recommendations:
- Review Privacy Policies: Thoroughly read and understand the privacy policies and terms of service of any AI platform before use.- Limit Sensitive Data Sharing: Avoid sharing personal or sensitive information when interacting with AI models, especially those with unclear data handling practices.- Stay Informed: Keep abreast of news and updates regarding the AI platforms you use, as policies and practices can evolve.
By staying informed and cautious, users can better protect their privacy while leveraging the capabilities of AI models.
🎧 Related Podcast Episode
Conclusion
Qwen2.5-Max has proven itself as a powerful AI model, capable of competing with—and even outperforming—established leaders. With state-of-the-art performance in key AI benchmarks, it represents a significant step forward in AI development.
As Alibaba continues to refine its AI capabilities, Qwen2.5-Max could reshape the competitive AI landscape, influencing how businesses, developers, and researchers use AI technologies.
References
[1] Alibaba claims its new AI model can beat DeepSeek, ChatGPT [2] Alibaba Launches Qwen2.5-Max AI Model To Challenge Rivals [3] Alibaba unveils Qwen2.5-Max, claiming AI superiority [4] Move over DeepSeek: Alibaba’s Qwen2.5-Max surpasses DeepSeek-V3 in benchmarks


