A federal judge just forced OpenAI to hand over millions of user conversations. If you’re not running AI locally yet, this is your warning shot.
The Bombshell Ruling
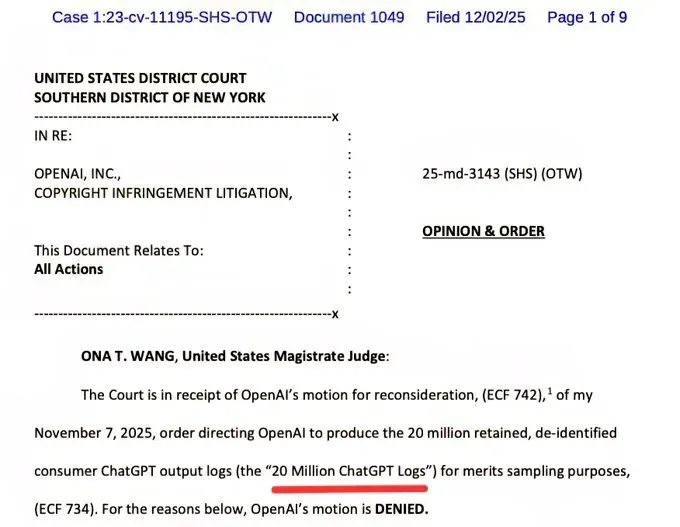
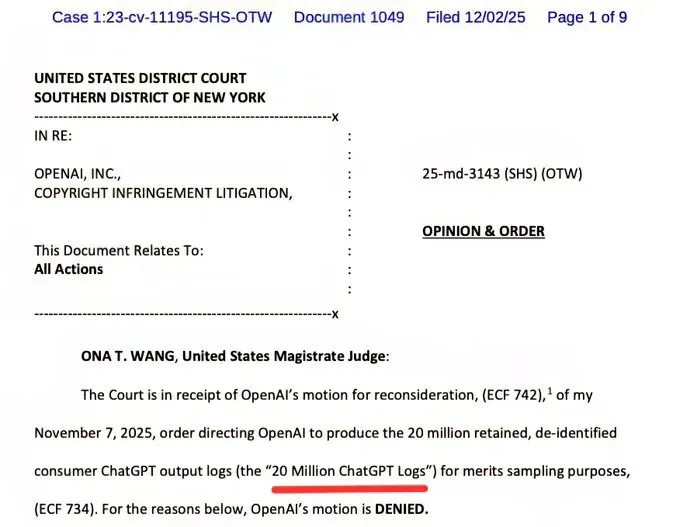
On December 2, 2025, U.S. Magistrate Judge Ona T. Wang delivered a crushing blow to OpenAI’s privacy arguments—and by extension, a wake-up call to anyone who’s ever typed something sensitive into ChatGPT. In a decisive 9-page order, Judge Wang denied OpenAI’s desperate motion for reconsideration and confirmed her earlier ruling: OpenAI must turn over 20 million de-identified ChatGPT conversation logs to plaintiffs in the massive copyright infringement lawsuit led by The New York Times and other major publishers.
This isn’t just another legal skirmish in Silicon Valley. This is 20 million real conversations—your conversations, perhaps—now sitting in a discovery pile, being analyzed by lawyers and expert witnesses. And if you think “de-identified” means your data is safe, we need to talk.
Related: OpenAI has faced massive GDPR violations before, including a €15 million fine for failing to report a ChatGPT data breach within 72 hours.


What Just Happened?
The backstory is complex, but the implications are crystal clear. Since May 2024, news organizations including The New York Times, Chicago Tribune, and MediaNews Group have been demanding access to ChatGPT output logs to prove their copyright infringement claims. They want to demonstrate that OpenAI trained its AI models on their copyrighted content without permission—and worse, that ChatGPT is now reproducing that content for users.
OpenAI fought this tooth and nail, arguing that:
- Producing the logs would violate user privacy- The sample size was disproportionate to the case needs- The data was mostly irrelevant (claiming over 99.99% of logs have no bearing on the case)- The burden of production was too high
Judge Wang systematically demolished every argument.
Download: gov.uscourts.nysd.612697.1049.0 gov.uscourts.nysd.612697.1049.0.pdf234 KB.a{fill:none;stroke:currentColor;stroke-linecap:round;stroke-linejoin:round;stroke-width:1.5px;}download-circle
The Judge’s Decisive Response
In her ruling, Judge Wang made several critical findings:
On Relevance: The logs aren’t just relevant for showing direct copyright infringement—they’re also crucial for evaluating OpenAI’s fair use defense and its claim that ChatGPT has “substantial non-infringing uses.” The judge noted that output logs without reproductions of copyrighted works are still relevant to understanding how users actually employ the technology.
On Proportionality: The 20 million logs represent less than 0.05% of the “tens of billions” of consumer ChatGPT output logs OpenAI retains in the ordinary course of business. Judge Wang found this sample size entirely reasonable.
On Privacy: Here’s where it gets interesting. The judge acknowledged OpenAI’s privacy concerns but concluded that multiple layers of protection adequately safeguard user privacy:
- The reduction from tens of billions to 20 million logs2. OpenAI’s internal de-identification process3. The existing protective order in the case4. “Attorneys’ eyes only” designation for the most sensitive materials
But the judge added a pointed footnote that should make everyone nervous: OpenAI spent 2.5 months de-identifying this entire 20-million-log sample. If OpenAI never intended to produce them, “it was unclear why the company invested time and money in de-identifying the entire sample.”
The implication? Either OpenAI changed its litigation strategy mid-stream, or it de-identified everything “as a discovery tactic, or for some other reason that has not been identified.” The judge noted, “Neither bode well for OpenAI.”
The Math That Should Terrify You
Let’s break down what we actually know:
- OpenAI retains “tens of billions” of consumer ChatGPT logs in ordinary course of business- The 20 million sample represents 0.05% of total retained logs- This means OpenAI is sitting on somewhere between 40 to 200+ billion conversation logs- OpenAI has been collecting this data since at least December 2022- The company spent 12 weeks de-identifying just 20 million logs
Now do the math: If OpenAI retains everything by default (which the court documents confirm), and if this legal discovery motion succeeds in one case, what stops it from succeeding in another? What happens when the next lawsuit demands logs? Or when a government subpoena arrives? Or when a data breach occurs?
Your conversations aren’t ephemeral. They’re evidence waiting to be discovered.
”De-Identified” Doesn’t Mean “Anonymous”
OpenAI and Judge Wang both lean heavily on the fact that the logs are “de-identified” before production. This should provide cold comfort.
De-identification is a process of removing personally identifiable information (PII) like names, email addresses, phone numbers, and other obvious identifiers. But modern research has repeatedly demonstrated that de-identified data can often be re-identified through various techniques.
Context matters: Just this year, over 130,000 AI conversations from ChatGPT and other LLMs were exposed on Archive.org, revealing sensitive corporate financial data, settlement details, and confidential information—despite users believing their chats were private.
The Re-Identification Problem
A landmark 2019 study in Nature Communications showed that 99.98% of Americans could be correctly re-identified in any dataset using just 15 demographic attributes. Another study found that supposedly anonymized web browsing histories could be re-identified with 72-92% accuracy using machine learning.
Here’s why de-identification isn’t enough:
Contextual Clues: If you discussed specific projects, company names, personal relationships, locations, or events in your ChatGPT conversations, those contextual clues create a unique fingerprint.
Writing Style: Your writing patterns, vocabulary, sentence structure, and preferred phrases are nearly as unique as a fingerprint. Stylometric analysis can identify authors even in “anonymized” texts.
Cross-Referencing: If any piece of de-identified data can be linked to a public dataset, census information, social media, or other sources, re-identification becomes trivial.
Temporal Patterns: When you chat, how often, and about what topics creates behavioral patterns that can identify you even without traditional PII.
The reality? De-identification is a legal checkbox, not a security guarantee. It makes casual identification harder, but it won’t stop a determined adversary—or even a sophisticated research team—from figuring out who said what.
The threat landscape is real: Nation-state actors are already weaponizing ChatGPT for espionage and malware development, and OpenAI has confirmed at least 10 malicious AI campaigns from China, Russia, Iran, and North Korea. If adversarial governments are mining AI conversations for intelligence, your “de-identified” data is a target.
What This Means for You
If you’ve used ChatGPT for anything sensitive, personal, or proprietary, here’s your reality check:
You Might Already Be Exposed
According to the court documents, the 20 million log sample spans December 2022 through November 2024. If you used ChatGPT during that window, your conversations might be in this sample. They’re now in the hands of:
- Plaintiff attorneys- Defense attorneys- Expert witnesses- Technical consultants- Anyone those parties decide to share them with under the protective order
Your Data Is Permanent
The myth of “deleted means gone” died years ago in data centers, but it’s worth restating: When you use cloud AI services, your data becomes part of a massive retention system. OpenAI’s court filings confirm they retain “tens of billions” of logs as standard practice. Even if you delete conversations from your account, the data persists in OpenAI’s backend systems.
Judge Wang’s order notes that OpenAI had actually been deleting some API and enterprise ChatGPT logs, plus consumer logs marked for deletion by users—until she issued a preservation order in May 2025 stopping all deletion. That preservation order was eventually lifted in September 2025, but the damage is done: OpenAI now has records they might have otherwise deleted, specifically because of litigation.
Future Legal Exposure
This case sets a precedent. If courts will order production of 20 million logs in a copyright case, what happens in:
- Divorce proceedings where ChatGPT usage is relevant?- Employment disputes involving proprietary information?- Criminal investigations?- National security cases?- Regulatory investigations by the FTC, SEC, or other agencies?
Your ChatGPT conversations are no longer private musings. They’re potential evidence in any future legal matter involving you or your company.
The “I Have Nothing to Hide” Fallacy
Some people will shrug this off. “I don’t use ChatGPT for anything sensitive,” they’ll say. “Let them have the logs.”
This fundamentally misunderstands how privacy erosion works.
Privacy Is Cumulative
You might not care that your ChatGPT logs are accessible in this case, under this protective order, with this specific set of attorneys. But data doesn’t stay contained. The more places your information exists, the more attack surfaces exist for:
- Future breaches- Expanded legal discovery- Whistleblowers- Insider threats- Government surveillance- Commercial exploitation
Every time data moves from “private” to “accessible under certain conditions,” the conditions expand. Discovery orders become precedents. Protective orders get breached. Security measures fail.
Chilling Effects Are Real
The knowledge that your AI conversations might become evidence changes behavior. This is called a “chilling effect,” and it’s a well-documented phenomenon in privacy research.
When people know they’re being watched or recorded, they:
- Self-censor- Avoid certain topics- Don’t experiment freely- Fail to explore controversial or unconventional ideas- Don’t develop thoughts fully before self-editing
This matters even if you personally “have nothing to hide.” A society where people constantly self-censor because any conversation might become evidence isn’t a free society. It’s a surveillance state with extra steps.
Your Data Outlives Your Threat Model
You might be a law-abiding citizen with no legal worries today. But:
- Laws change- Governments change- Your employment situation changes- Your relationships change- Your business ventures change- Your country’s political climate changes
Data retained today can become weaponized tomorrow against activities that are legal and normal today but controversial or illegal tomorrow. This isn’t paranoia—it’s literally how totalitarian governments use data surveillance, and it’s how many democracies backslide into authoritarianism.
Why This Ruling Changes Everything
Judge Wang’s order isn’t just about copyright law. It establishes several dangerous precedents:
1. “De-Identification” Is Sufficient Protection
By accepting OpenAI’s de-identification process as adequate privacy protection (alongside a protective order), the court has essentially endorsed a standard that privacy researchers know is insufficient. Future courts will cite this precedent.
2. Sample Size Can Be Massive
Twenty million records is a staggering amount of data. The fact that this represents only 0.05% of OpenAI’s total logs doesn’t make it reasonable—it makes the total retention terrifying. But the court found this proportional, which means future discovery requests can be similarly massive.
3. “Relevance” Is Broadly Construed
Judge Wang found that logs without copyright infringement were still relevant to OpenAI’s defenses. This broad interpretation of relevance means that nearly any log could be deemed discoverable for nearly any purpose in future litigation.
4. Commercial Privacy Promises Are Legally Unenforceable
OpenAI made strong privacy promises to users. The company’s blog post in response to the ruling emphasizes their commitment to fighting for user privacy. But when push came to shove in federal court, those promises meant nothing. The company had no legal grounds to refuse production based on user privacy expectations.
This is the cold reality: Terms of Service privacy commitments are not a shield against legal discovery. If a judge orders production, it’s happening.
The Solution: Local AI
Everything we’ve discussed leads to one inevitable conclusion: If you care about privacy, you cannot use cloud-based AI services for anything sensitive.
The technology exists today to run powerful AI models entirely on your own hardware. Here’s why it matters:
True Privacy
When an AI model runs on your computer, your data never leaves your computer. There are no logs to be subpoenaed. No server-side retention. No discovery requests. No legal ambiguity.
The conversation exists between you and your machine, and nowhere else.
No Cost Per Query
Cloud AI services charge by the token. Heavy users can rack up significant bills. Local AI has a one-time hardware cost, then free unlimited usage forever. No API bills. No subscription fees. No rate limits.
For businesses and power users, the ROI is obvious: A $2,500 GPU pays for itself in months compared to heavy ChatGPT API usage.
Offline Capability
Local AI works without internet connectivity. This provides resilience, independence, and an additional layer of security (no network traffic means no network interception).
Customization
Local models can be fine-tuned on your specific data without that data ever leaving your control. You can create specialized models for your industry, your company, or your personal use case.
Independence from Provider Changes
Cloud AI providers can change models, deprecate features, adjust pricing, or shut down entirely. Local AI is yours forever. The model files aren’t going anywhere.
How to Run Local AI
The good news: Running local AI is easier than ever. Here’s the practical reality:
Hardware Requirements
Minimum viable setup:
- Used NVIDIA RTX 3060 (12GB VRAM): ~$300-400- 32GB system RAM- 1TB SSD storage- Total cost: ~$1,000 for a capable system
Recommended setup for serious use:
- NVIDIA RTX 4090 (24GB VRAM) or RTX 5090: ~$2,000-2,500- 64GB system RAM- 2TB NVMe SSD storage- Total cost: ~$3,000-4,000 for high-performance system
For Mac users:
- M1/M2/M3 Mac with 32GB+ unified memory works excellently- No additional GPU needed
Software Options
Ollama (recommended for beginners):
- Dead simple installation- Excellent model library- Great command-line interface- Free and open source
LM Studio (recommended for GUI users):
- User-friendly graphical interface- Easy model management- Cross-platform- Free
Jan (recommended for privacy purists):
- Open source and privacy-first- Offline-first design- Active development- Free
Text Generation WebUI (recommended for power users):
- Highly customizable- Extensive features- Active community- Free and open source
Model Selection
Start with these proven open-source models:
For general use (7-13B parameters):
- Mistral 7B (fast, capable, runs on modest hardware)- Llama 3.1 8B (excellent instruction-following)- Qwen 14B (strong reasoning capabilities)
For advanced use (30-70B parameters):
- Llama 3.1 70B (competitive with GPT-4 for many tasks)- Qwen 72B (excellent technical knowledge)- Mixtral 8x22B (efficient large model)
Performance Expectations
With a modern GPU:
- 7B models: 40-100 tokens/second (faster than you can read)- 13B models: 20-50 tokens/second (still very fast)- 70B models: 5-20 tokens/second (slower but highly capable)
For context: ChatGPT responds at roughly 20-40 tokens/second, so local AI with a decent GPU is fully competitive with cloud services on performance.
Real-World Use Cases for Local AI
Local AI isn’t just for privacy paranoids. It’s genuinely useful for:
Professional Applications
Software Development:
- Code review and debugging without exposing proprietary code- Documentation generation- Architecture discussions with full codebase context- No risk of leaking trade secrets (unlike the recent xAI-OpenAI trade secret theft case where an engineer allegedly uploaded an entire codebase)
Legal Work:
- Client matter analysis- Document review and summarization- Legal research assistance- Full attorney-client privilege protection
Healthcare:
- Clinical decision support without HIPAA concerns- Medical research assistance- Patient data analysis- Complete compliance with health privacy regulations
Financial Services:
- Market analysis with proprietary data- Trading strategy development- Client portfolio review- Full SEC compliance
Journalism:
- Source protection- Story research- Interview preparation- Whistleblower communications
For comprehensive guidance on AI compliance: Check out this ChatGPT & AI Tools GDPR Compliance Framework for organizations implementing AI while maintaining privacy standards.
Personal Applications
Private Therapy and Mental Health:
- Mental health journaling- Cognitive behavioral therapy exercises- Anxiety management- Depression support- No risk of insurance implications or records
Sensitive Personal Planning:
- Divorce strategy- Estate planning- Conflict resolution- Relationship issues- Financial planning with actual numbers
Creative Work:
- Novel writing without exposure- Screenplay development- Music composition- Art project planning- Full creative privacy
Education:
- Test preparation- Essay development- Research assistance- Learning support- No academic integrity concerns
The Counter-Arguments (And Why They’re Wrong)
Let’s address the inevitable pushback:
“Cloud AI is more powerful”
Response: Not anymore. Open-source models like Llama 3.1 70B and Qwen 72B are competitive with GPT-4 for most tasks. The capability gap has closed dramatically in 2024-2025. Unless you need absolute cutting-edge performance for specialized tasks, local AI is entirely sufficient.
”I don’t have the technical skills”
Response: If you can install applications on your computer, you can run local AI. Tools like Ollama and LM Studio have graphical installers and intuitive interfaces. It’s literally easier than setting up many consumer software products.
”The hardware is too expensive”
Response: A capable local AI setup costs $1,000-3,000. If you’re a professional using AI regularly, this pays for itself in months compared to ChatGPT subscriptions or API costs. If you’re a business, this is a rounding error compared to your legal and compliance costs—and infinitely cheaper than the potential liability of a data breach or discovery disaster.
”OpenAI promises not to train on my data”
Response: OpenAI’s Enterprise customers get contractual guarantees about training data. But as this court case demonstrates, legal discovery overrides Terms of Service. Your data is still stored, still accessible to subpoenas, and still vulnerable to breaches.
More importantly: Every cloud AI provider can change their policies. Terms of Service are updated constantly. Today’s promise is tomorrow’s footnote in a privacy policy update.
”De-identification protects me”
Response: As discussed extensively above, de-identification is not anonymization. It’s a speed bump, not a roadblock. Modern re-identification techniques are sophisticated and effective.
”I trust OpenAI/Google/Anthropic”
Response: This isn’t about trust. It’s about capabilities and incentives:
- Legal obligations: Courts can compel data production regardless of company promises- Government requests: National security letters, warrants, and subpoenas happen constantly- Breaches: Every company gets hacked eventually; it’s not if but when- Insider threats: Employees with access are human beings with financial pressures and vulnerabilities- Business model changes: Companies get acquired, leadership changes, business models pivot
For perspective: Meta AI faces similar privacy controversies across Instagram, Facebook, and WhatsApp, with opaque opt-out mechanisms and unclear data usage policies. This pattern extends across all major AI platforms.
The only way to guarantee privacy is to ensure the data never exists in a format others can access. That means local AI.
What You Should Do Right Now
Here’s your action plan:
Immediate Steps (Today)
- Stop using ChatGPT for sensitive topics immediately. This includes:
- Anything about your business that competitors shouldn’t know- Personal health or mental health discussions- Legal matters- Financial planning- Relationship issues- Anything you’d be uncomfortable with appearing in a court filing2. Review your ChatGPT history. Go through your conversations and delete anything sensitive. (Yes, OpenAI still has server-side logs, but at least remove the easy access point.)3. Disable chat history in ChatGPT settings. This won’t help with past data, but it prevents future retention.4. Tell your team/family. If you run a business or have family members using ChatGPT, brief them on these risks immediately.
Short-Term Steps (This Month)
- Research local AI options. Spend a few hours reading about Ollama, LM Studio, and other local AI tools. Watch YouTube tutorials. Join relevant subreddits or Discord communities.2. Assess your hardware. Do you have a gaming PC with a decent GPU? A recent Mac? If yes, you might already have capable hardware. If not, start budgeting for an upgrade.3. Test free options first. Before investing in hardware, try running smaller models on your existing computer to get a feel for the workflow.4. Develop a data classification policy. Categorize information types:
- Public: Can use any AI- Internal: Local AI only- Confidential: Local AI only with additional security- Secret: No AI, period
Learn from enforcement: Study the 10 major GDPR fines and accountability lessons to understand how regulators are treating AI data processing violations. OpenAI’s €15M fine is just the beginning.
Long-Term Steps (This Year)
- Invest in capable hardware. Whether that’s a dedicated AI workstation, upgrading your existing computer, or building a custom rig, make the investment.2. Set up your local AI environment. Install Ollama or LM Studio, download a few models, and integrate them into your workflow.3. Train your team. If you run a business, provide training on local AI tools and updated data handling policies.4. Document your approach. Create written policies about AI usage, data handling, and privacy protection. This protects you legally and operationally.5. Advocate for change. Push back against cloud AI mandates in your workplace. Talk to colleagues about privacy risks. Vote with your wallet by supporting privacy-respecting AI companies.
The Bigger Picture: Where This Goes Next
This court ruling is one data point in a larger trend. We’re entering an era where:
AI Logs Become Standard Discovery
Expect plaintiff attorneys to routinely request AI conversation logs in:
- Patent disputes- Trade secret cases- Employment litigation- Divorce proceedings- Criminal investigations- Regulatory inquiries
Every lawsuit will now potentially include discovery requests for “all AI-generated content related to…” This will become standard practice.
Context: 2025 has witnessed unprecedented surge in cyber attacks and data breaches with ransomware attacks rising 126% globally. Your AI conversation logs are just another attack surface waiting to be exploited.
Re-Identification Technology Advances
As AI becomes more powerful, so do re-identification techniques. What seems anonymized today will be trivially de-anonymized in five years.
Data Retention Periods Increase
Companies will face pressure to retain data longer for legal compliance, even as users demand deletion rights. Expect this tension to worsen.
Government Surveillance Expands
If courts find 20 million logs proportional in civil discovery, imagine what national security agencies will claim is reasonable for surveillance purposes.
Privacy Regulations Lag Behind
GDPR, CCPA, and other privacy regulations are still playing catch-up with traditional data. They’re completely unprepared for the scale and complexity of AI conversation logs.
The Choice Is Yours
Judge Wang’s ruling stripped away any remaining illusion of privacy in cloud AI services. Your conversations are not private. They’re not ephemeral. They’re not protected by Terms of Service or corporate promises.
They’re evidence.
You have exactly two choices:
- Accept that every conversation you have with cloud AI services is potentially discoverable, might be subpoenaed, could be breached, and will live forever in corporate databases you don’t control.2. Buy a GPU, run local AI, and actually protect your data.
There is no third option. There’s no middle ground where cloud providers “promise really hard” to protect your privacy. Judge Wang made that clear: when courts come knocking with discovery orders, privacy promises evaporate.
🎧 Related Podcast Episode
Conclusion
Twenty million ChatGPT conversations just became evidence in a federal lawsuit. That number represents less than 0.05% of OpenAI’s total logs, which means tens of billions of conversations are sitting in databases, waiting for the next subpoena, the next breach, the next overly broad discovery request.
Maybe none of those 20 million conversations are yours. Maybe you’ll never be involved in litigation where your AI usage is relevant. Maybe you’ll never face a data breach that exposes your private musings to the world.
But do you want to bet on “maybe”?
The technology exists today to run powerful AI entirely on your own hardware, under your complete control, with zero cloud exposure. It’s more affordable than ever. It’s easier to use than ever. It’s more capable than ever.
The question isn’t whether you should run local AI.
The question is: what are you waiting for?
Additional Resources
Local AI Software
- Ollama: https://ollama.ai/- LM Studio: https://lmstudio.ai/- Jan: https://jan.ai/- Text Generation WebUI: https://github.com/oobabooga/text-generation-webui
Hardware Guides
- r/LocalLLaMA (Reddit community)- “The Complete Guide to Running LLMs Locally” (various blog posts)- PCPartPicker for hardware compatibility
Model Repositories
- Hugging Face: https://huggingface.co/- Ollama Model Library: https://ollama.ai/library- TheBloke on Hugging Face (quantized models)
Privacy Resources
- Electronic Frontier Foundation: https://www.eff.org/- Privacy International: https://privacyinternational.org/- “Practical Cryptography for Developers” (free book)- Data Protection Officers and AI: Navigating Privacy in the Age of Machine Learning- The Privacy Implications of Meta AI: User Data and AI Integration
Legal Context
- Case: In Re: OpenAI, Inc., Copyright Infringement Litigation, No. 1:25-md-03143 (S.D.N.Y.)- Document 1049 (Judge Wang’s December 2, 2025 Order)
Article based on U.S. District Court Southern District of New York Case 1:23-cv-11195-SHS-OTW Document 1049, Filed 12/02/25, and extensive research on local AI implementations, privacy considerations, and data security best practices.
Disclaimer: This article provides analysis and opinion on legal proceedings and technology. It is not legal advice. Consult qualified legal counsel for specific situations. All product names, trademarks, and registered trademarks are property of their respective owners.


